개요
스케줄러를 사용할 때, 서버가 하나뿐인 환경에서는 동시에 같은 스케줄링 작업이 중복해서 실행되는 것을 고려할 필요가 없습니다.
그러나 둘 이상의 서버를 사용하는 분산 환경에서는 클러스터링이 필요합니다. 세션 기반 로그인을 분산 환경에서 사용해보았다면 레디스나 JDBC를 이용해서 세션 클러스터링을 고민해보거나 시도해본 경험이 있을 것입니다.
스케줄러도 동일합니다. 분산 환경에서 스케줄링한 작업이 동시에 한 번만 실행하는 것을 보장해주기 위해 클러스터링이 필요합니다.
이에 대한 해결방법은 두 가지입니다.
첫째, 스케줄러 락을 제공하는 라이브러리인 shedlock을 사용하는 것
둘째, 스프링이 제공하는 스케줄러 대신 quartz를 사용하여 스케줄러 클러스터링을 하는 것
저는 전자의 방법인 shedlock을 이용해보겠습니다. 현재 진행중인 프로젝트에 빠르게 적용할 수 있고 quartz를 사용하기 위해서는 추가 학습을 진행해야 합니다. 추후 프로젝트를 끝낸 후 quartz에 대한 학습을 진행해보는 것으로 하겠습니다.
shedlock은 공통의 저장소에 스케줄러 락에 대한 정보를 저장하는 기능을 제공하는 심플한 라이브러리입니다. 어노테이션 기반으로 동작하기 때문에 설정 정보를 제외하면 따로 코드를 추가할 필요도 없습니다.
shedlock을 사용하는 방법은 해당 깃허브에 상세한 사용법과 jdbc, redis 등 적용할 수 있는 다양한 방법을 소개하고 있습니다. 문서를 읽어보시면 쉽게 적용하실 수 있습니다.
적용
1. 의존성
해당 라이브러리를 사용하기 위해서 다음과 같이 의존성을 추가해줍시다.
build.gradle
//scheduler
implementation 'net.javacrumbs.shedlock:shedlock-spring:5.7.0'
implementation 'net.javacrumbs.shedlock:shedlock-provider-jdbc-template:5.7.0'shedlock-spring
- 스프링 환경에서
shedlock을 사용할 수 있게 해주는 라이브러리입니다.
shedlock-provider-jdbc-template
- 스케줄러 락을 사용하기 위한 방법으로
jdbc를 통해 저장소에 접근할 것입니다. redis를 포함하여 다양한 방법을 제공하고 있으므로 해당 github를 참고하시어 원하는 방법을 선택하실 수 있습니다.
2. 설정
저는 접근 방법으로 jdbc를 선택했으니 @Configuration에 다음과 같은 설정을 추가해줍니다.
...
@Configuration
public class ScheduledConfig implements SchedulingConfigurer {
...
@Bean
public LockProvider lockProvider(DataSource dataSource) {
return new JdbcTemplateLockProvider(dataSource);
}
}스케줄러 락에 관한 정보를 저장할 스키마를 추가하고 어플리케이션 실행 시 해당 DDL이 실행될 수 있도록 설정을 추가해줍니다.
src/main/resources/sql/shedlock-schema.sql
DROP TABLE IF EXISTS shedlock;
CREATE TABLE shedlock
(
name VARCHAR(64) NOT NULL,
lock_until TIMESTAMP(3) NOT NULL,
locked_at TIMESTAMP(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),
locked_by VARCHAR(255) NOT NULL,
PRIMARY KEY (name)
);application.yml
spring:
sql:
init:
schema-locations: classpath:sql/shedlock-schema.sql
encoding: UTF-8
mode: always3. 코드
이제 기존에 스프링 스케줄러를 이용하던 작업에 스케줄러 락을 위한 어노테이션을 추가해줍니다.
@EnableSchedulerLock(defaultLockAtMostFor = "PT60S")
public class GradeScheduler {
...
@Async
@Scheduled(cron = "0 * * * * *")
@SchedulerLock(name = "Update_User_Grade", lockAtLeastFor = "PT10S")
@Transactional
public void updateUserGrade() {
...
log.info("스케줄링이 실행되었습니다.");
...
}
}@EnableSchedulerLock(defaultLockAtMostFor = "PT60S")
- 스케줄러 락을 활성화합니다.
defaultLockAtMostFor는 실행 노드가 죽었을 때 락을 유지하기 위한 최대 시간에 대한 설정입니다. 일반적인 상황에서는 작업이 완료되는 즉시 락이 해제됩니다.
@SchedulerLock(name = "...", lockAtLeastFor = "PT10S")
- 해당 어노테이션이 달린 메서드에 락을 겁니다.
name을 통해 이름을 지정하면, 동시에 같은 이름을 가진 하나의 작업만이 실행됩니다.lockAtLeastFor는 락이 유지되는 최소한의 시간입니다. 현재 표기법은ISO8601을 따라 작성했으며10s처럼 작성할 수도 있습니다.- 별도의
lockAtMostFor를 통해 최대 잠금 시간을 작성하지 않으면@EnableSchedulerLock의 설정을 따릅니다.
4. 실행
인텔리제이의 기능을 이용해 2개의 프로젝트를 띄우고 콘솔의 로그를 확인하면 정상적으로 적용된 것을 확인할 수 있습니다.
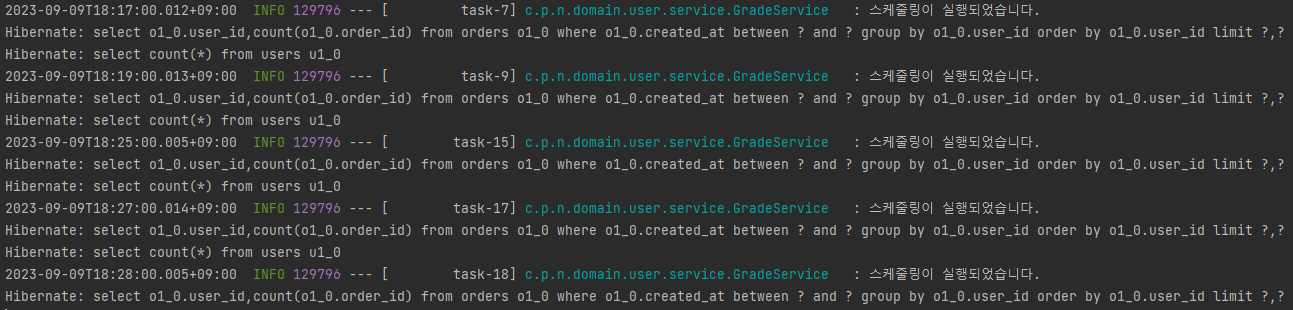

데이터베이스에도 스케줄러 락에 관한 정보가 저장된 것을 확인할 수 있습니다.
'Spring' 카테고리의 다른 글
| @WebMvcTest와 테스트 코드 개선하기 (0) | 2023.10.04 |
|---|---|
| 낙관적 락과 동시성 테스트하기 (0) | 2023.09.16 |
| 스프링 시큐리티 인증 프로세스와 데이터베이스 (0) | 2023.08.12 |
| 스프링 빈에 관하여 (0) | 2023.06.30 |
| 스프링 부트가 제공하는 프로덕션 준비 기능 (0) | 2023.05.29 |



